1. 확률의 기본 개념
1-1. 확률실험(random experiment)과 표본공간(sample space)
1. 확률실험(random experiment)
사전에 실험의 결과를 확실하게 예측하지 못하는 실험을 의미.
2. 표본공간(sample space)
표본공간(sample space)이란 확률실험의 결과(outcome)로 얻을 수 있는 모든 가능한 결과 치의 집합을 의미.

3. 사상(event)
사건 또는 사상(event)은 실험 또는 관찰로 인해 발생하는 하나 또는 두 개 이상의 결과의 집합체. 사상은 표본 공간의 부분집합이며 특정한 조건에 해당하는 원소들로 구성되며 단순사건과 복합사건으로 나눌 수 있음. 단순사건(simple event)은 실험으로 인한 결과가 하나인 경우이고 복합사건(compound event)은 실험의 결과가 두 개 이상인 경우를 의미.
4. 상호배타적(mutually exclusive) 사상
동일한 표본공간에 대하여 정의된 두 사상 A와 B간에 공통된 원소가 하나도 없는 경우 두 사상을 상호배타적(mutually exclusive) 사상이라고 함. 동일한 표본공간에서 정의된 k개의 사상에 대해서도 각각 공통 원소가 존재하지 않는다면 k개의 사상은 상호배타적.
1-2. 확률의 정의
확률(probability)이란 사상이 발생할 가능성을 나타내는 0과 1 사이의 수
1. 이론적(사전적)확률(priori probability)
이론적 확률개념은 확률실험을 하지 않고도 발생할 모든 경우의 수를 알고 있고 특정 사건에 대한 경우의 수에 대해 상대도수를 계산할 수 있는 확률.

2. 실험적 확률(empirical probability)
확률실험을 n회 반복하였을 때 특정 사상 A가 m번 발생하였다면 사상 A가 발생할 확률은 상대도수의 극한치로 정의.

3. 주관적 확률(subjective probability)
주관적 확률은 확률을 개인의 지식, 정보, 경험 등의 주관적 요소에 의하여 측정하는 방법. 예를 들면 어떤 금융 전문가에게 하반기 금융시장의 경기가 호전될 확률을 자문하였을때 30%라고 대답한다면 이것이 주관적 확률인 것.
2. 확률의 법칙
2-1. 확률의 정의에 따른 기본법칙

2-2. 확률의 덧셈법칙(addition rule)
1. 덧셈법칙의 적용
동일한 표본공간에서 정의된 사상 A 또는 B가 발생할 확률

2. 덧셈법칙의 예외
두 사상 A와 B가 상호 배타적인 경우 교집합은 공집합이 되므로 교집합의 확률은 0.

2-3. 조건부 확률과 곱셈법칙
1. 조건부 확률(conditional probability)
특정한 사상이 이미 발생하였다는 조건하에서 다른 사상이 발생할 확률로 정의. 조건부 확률에서는 표본공간의 축소가 발생.
예를 들어 주사위를 던져서 2의 눈이 나올 확률은 1/6이지만 짝수라는 조건하에서 2의 눈이 나올 조건부 확률은 1/3로 계산

2. 독립사상(independent events)
한 사상의 발생이 다른 사상의 발생 확률에 영향을 미치지 않을 경우 두 사상은 상호 독립 (mutually independent)이라고 함.

한 사상의 발생이 다른 사상의 발생 확률에 영향을 준다면 두 사상은 상호 종속사상 (dependent events).
3. 확률의 곱셈법칙(multiplication rule)
동일한 표본공간에서 정의된 두 개의 사상에 대한 확률의 곱셈법칙(multiplication rule)은 두 사상이 동시에 발생할 확률을 의미. 곱의 확률 혹은 결합확률(joint probability)이라고도 함.

4. 곱셈법칙의 예외
만약 두 개의 사상 A, B가 상호 독립이라면 곱셈법칙의 예외적인 경우가 성립. 독립 사상에서는 P(A|B) = P(A)이므로 곱셈의 일반법칙을 나타내는 식에 대입하여 정리하면 독립 사상의 경우 교집합의 확률을 구하는 식은 개별 사상이 발생할 확률을 곱해주기만 하면 됨.

만약 상호 독립적인 사상이 k개가 존재한다고 할 때에도 곱셈법칙의 예외적인 경우를 적용 가능. 상호 독립적인 사상 E1, E2, ..., Ek가 있을 때 이들이 동시에 발생할 확률은 곱집합에 대한 확률이며 각 사상이 발생할 확률의 곱과 같음.

예) 어느 중소기업이 3년 후 부도가 날 확률이 다음과 같으며 각 기업은 업종이 다르므로 부도가 날 확률이 독립이라고 할 때 3년 후 3개의 기업이 모두 부도가 날 확률은 얼마인가?

해설 : 3개의 사건은 독립이므로 모두 부도가 날 확률은 3개의 사건이 발생할 확률을 모두 곱하면 된다. 4%×12%×30% = 0.144%
3. 총확률정리와 베이즈 이론
3-1. 총확률정리(total probability rule)
총확률정리(total probability rule)는 표본공간이 k개의 상호배타적인 사상으로 분할될 경우 임의의 사상 P(B)의 발생 확률로 계산됨.
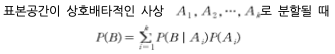
3-2. 베이지안 법칙(Bayes'formula)
베이지안 법칙(Bayes’ formula)을 적용하면 사후적 확률을 구할 수 있음. P(A)는 미리 주어진 사전적 확률(prior probability)이지만 사상 B라는 새로운 사건이 실제로 발생하였다면 P(A|B)의 사후적 확률(posterior probability)을 구할 수 있다.

어떠한 실험의 결과를 실수에 대응시켰을 때 그 값을 확률변수(random variables)라고 함. 확률변수는 무작위실험 결과에 의해 결정되는 변수로서 우연변수(chance variable)라고도 함. 하나의 확률실험에 대한 확률변수 전체는 대문자 X, Y, Z 등으로 나타내고 개별값은 소문자 x, y, z 등으로 나타냄.
확률변수는 그 특성에 따라 이산확률변수와 연속확률변수로 구분. 변수를 구분하는 기준은 변수를 셀 수 있는가의 여부.
4. 확률변수와 확률함수
4-1. 확률변수란?
어떠한 실험의 결과를 실수에 대응시켰을 때 그 값을 확률변수(random variables)라고 함. 하나의 확률실험에 대한 확률변수 전체는 대문자 X, Y, Z 등으로 나타내고 개별값은 소문자 x, y, z 등으로 나타냄.
1. 이산확률변수의 정의 및 특성
변수가 취할 수 있는 값을 하나하나 헤아려 열거할 수 있을 때 그 변수는 이산확률변수 (discrete random variables)가 됨. 확률실험 결과를 이산확률변수로 나타낼 수 있을 때 개별 확률변수 값에 대한 확률을 구할 수 있음. 이산확률변수를 갖는 확률분포를 이산확률분포(discrete probability distribution)라고 함.
<이산확률변수의 예>

2. 연속확률변수의 정의 및 특성
이산확률변수와는 달리 연속확률변수(continuous random variables)는 확률실험의 결과로 나타나는 사상이 주어진 실수구간 내에 속하는 어떠한 값도 취할 수 있음. 연속확률변수를 갖는 확률분포를 연속확률분포(continuous probability distribution)라고 함. 많은 수치 자료가 연속확률변수의 형태를 보이고 있으며 확률변수가 셀 수 있는 경우라도 그 경우의 수가 매우 많으면 연속확률변수로 취급.
예를 들어 특정 은행을 찾아오는 1일 고객의 수는 셀 수 있지만 경우의 수가 너무 많으므로 연속확률변수로 취급하는 것.
연속확률변수에 대한 확률을 계산할 때 가장 특징적인 것은 개별 변수값에 대한 확률을 0이 라고 보는 것. 연속확률변수는 상한값이나 하한값이 주어질 수는 있지만 해당 실수구간의 모든 실수를 취할 수 있기 때문에 정확하게 특정한 한 값이 나올 확률은 0에 가깝다고 본다. 예를 들어 집에서 회사까지 출근시간이 최소 30분에서 최대 1시간이 걸린다고 할 때 정확히 35분이 걸릴 확률은 (비록 정확히 35분이 걸릴 수 있다고 해도) 0에 근접. 따라서 연속확률변수는 항상 구간으로 확률을 계산.
<연속확률변수의 예>

4-2. 확률함수(probability function)
1. 확률함수란?
확률함수란 확률변수 X가 어떤 특정 실수 x를 취할 확률을 함수로 나타낸 것. 확률실험의 결과를 실수로 바꿔주는 작업을 수행하는 것이 확률변수라면 확률변수에 대응하는 확률을 할당하는 것이 확률함수의 역할이라고 할 수 있음. 주로 f(x)로 표기. 연속확률변수에서는 확률분포가 이루는 곡선 아래의 면적이 1로도 계산.

2. 누적확률함수(cumulative distribution function)
확률변수 X가 특정한 실수값 이하일 확률을 나타내는 확률함수를 누적확률함수(cumulative distribution function:cdf)라고 함. 누적확률함수는 F(x)라고 표기하며 확률변수가 이산 이든 연속이든 관계없이 정의 가능.

3. 확률분포(probability distribution)의 개념
모든 확률변수들은 그 특성에 따라 다양한 확률분포를 따르게 됨. 확률분포는 확률변수와 그에 따른 확률이 어떻게 분포되는 가를 보여주는 것. 통계분석은 확률변수가 어떤 분포를 따르는가를 파악한 후에 그 분포의 성질을 이용하여 수행되는 경우가 대부분. 확률변수들이 어떤 분포를 따르는가를 파악하는 것은 쉬운 것이 아니지만 현실에서 일어나는 사건에 대한 확률분포는 대부분 소수의 특정 분포를 따르게 됨. 따라서 확률변수가 발생하는 상황에 가장 적합한 확률분포를 찾을 수 있다면 통계분석을 비교적 용이하게 수행할 수 있는 것.
확률변수의 특성에 따라 이산확률변수를 취하게 되는 이산확률분포와 연속확률분포를 취하게 되는 연속확률분포로 크게 나눌 수 있음.
참고문헌 : Big Data 시대에 반드시 알아야 할 기초 통계지식/Ubion
'통계학 > 기초통계학' 카테고리의 다른 글
| 9차시 - 확률변수의 특성 및 이산확률분포 (0) | 2020.02.14 |
|---|---|
| 8차시 - 확률변수의 다양한 특성 (0) | 2020.02.12 |
| 6차시 - 다양하게 활용되는 조사방법2 (0) | 2020.02.09 |
| 5차시 - 다양하게 활용되는 조사방법1 (0) | 2020.02.09 |
| 4차시 - 다양하게 활용되는 자료측정방법 (0) | 2020.02.09 |



